Streams Aren’t Tables — Until You Index Kafka

Leo Delmouly
This is part 2 of a new series on modern real-time data architectures.
My last blog ended with a question:
"What if Kafka was queryable?"
it’s a challenge to how we think about real-time data. Kafka powers the modern event-driven stack. But when it comes to analysis, Kafka is strangely out of reach.
Business users don’t want streams. They want answers:
- What just happened?
- Why did it happen?
- How often has it happened before?
Yet if the data lives in Kafka, it’s often invisible to anyone who isn’t writing Java consumers or Flink jobs.
Kafka doesn't have indexes!
Kafka is brilliant for transporting events, not for interacting with them.
There are no indexes. No schemas. No constraints. Just raw logs.
That’s by design. It’s what gives Kafka its power as a stream processor.
But it’s also what makes analytics on Kafka painfully hard.
If you’ve ever tried to run a SQL query against Kafka, you’ve likely experienced:
- Full topic scans that time out
- Inefficient filters that parse every message
- Lack of partition awareness that crushes performance
Kafka gives you offsets and timestamps. Perfect for message delivery, not exploration.
But analysts don’t think in offsets. They think in questions:
- How many failed logins happened in the last hour?
- Which transactions exceeded $10,000?
- What device types saw a spike in errors yesterday?
And here’s the problem:
Kafka isn’t built to answer those kinds of questions.
Let’s break down why and what it takes to change that.
The Illusion of Choice
When teams want to run queries over Kafka, they turn to:
- KSQL – Limited syntax, hard to scale, dev focused.
- Apache Flink – Powerful, but not ad hoc. Definitely not analyst-friendly (unless they like reading engineering books).
- Sync jobs to DWH – Introduces delay, complexity, and cost.
- Custom consumers – Brittle, bespoke, hard to maintain.
You either sacrifice performance, usability, or data freshness. Usually all three.
Each of these introduces friction. And in practice, teams give up or settle for less:
- Delayed dashboards
- Weekly batch jobs
- Duplicate pipelines
Meanwhile, Kafka is sitting on this huge pile of valuable data... that nobody can touch without weeks (months?) of work.
So... We Tried Something Different
Instead of moving the data to an analytical system, we asked:
What if you brought analytical behaviour to Kafka?...
That starts with indexing.
We built a lightweight indexing layer that sits over Kafka topics and exposes queryable metadata without moving the raw data.
Here’s what that unlocked:
- WHERE clause pushdown: only scan messages that matter
- Aggregations on the fly: compute metrics across partitions
- Key/value search: instantly find events without full scans
- Time-based slicing: jump straight to the window you care about
Why Index Kafka?
Because offsets and timestamps aren’t enough.
They’re great for replaying streams.
They’re terrible for exploring data.
Let’s take a common analytics question:
“How many failed logins occurred in the last 30 minutes for users in Europe?”
Without indexing, your engine does this:
- Read every event in the topic
- Deserialize and parse each one
- Evaluate filters in-memory
- Aggregate on the fly
Result: Minutes (or hours) of compute time.
With indexing:
- You jump straight to the relevant time window
- You know which partitions to scan
- You use pre-built field indexes to jump directly to matching records
Result: Second response.
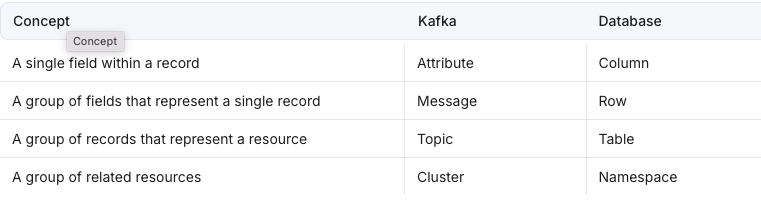
Stream vs Tables (a Quick Detour)
This all ties into one of the most underappreciated ideas in data engineering:
Streams and tables are two views of the same data.
A stream is a never-ending log.
A table is a snapshot of that log at a point in time.
The two aren’t opposites – they’re perspectives:
- A stream paused in time is a table.
- A table updated over time is a stream.
Indexing bridges that gap.
It lets Kafka act like a table — without changing the underlying data.
So instead of loading everything into a DWH and backfilling metrics, you can:
- Query Kafka directly with SQL
- Refresh metrics in real time
- Eliminate fragile batch syncs
- Enable real-time exploration, modeling, and debugging
All without duplicating data. All from the stream itself.
This turns Kafka from a write-only firehose into a powerful, queryable system of record.
So what changed?
With indexing in place, Kafka finally starts to behave like more than just a dumb pipe:
- Fast, expressive queries
- Zero ETL overhead
- Live answers, not lagging dashboards
Real-time becomes explorable. Analysts stop waiting. Engineers stop patching pipelines.
But here's the bigger picture:
Indexing is just the first step toward treating Kafka like a database.
To unlock real analytics (real reliability, real unification), we need something more.
That’s where Apache Iceberg comes in.
Iceberg is quickly becoming the new standard for how data is stored, versioned, and queried at scale. It brings tables to the modern data stack — open, atomic, queryable tables.
And if Kafka is where real-time data is born, then Iceberg is where that data becomes durable, discoverable, and usable by everyone.
In the next post, we’ll explore how Iceberg quietly became the default table format and why getting Kafka data into it is now a top priority.
🔍 Want to See What Indexed Kafka Feels Like?
👀 Check out the demo
📖 Or explore more at streambased.io