Kafka Is Fast — Getting Answers From It Isn’t

Leo Delmouly
This is part 1 of a new series on modern real-time data architectures. Next up: How We Index Kafka for 100x Faster Analytics
My journey with Kafka started 8 years ago, back when real-time was still seen as a luxury thing. I wasn’t tuning brokers or writing serializers. I was in the field, in sales, sitting front-row as companies moved from batch systems to real-time thinking.
And I saw it happen again and again: Developers lit up. Engineers shipped faster. Entire product lines came alive.
Fast forward to today: Kafka has seen, conquered and become the default. In nearly every industry, real-time isn’t a “nice to have” anymore, it’s survival.
User expectations demand it. Competitive pressure enforces it. And Kafka powers the shift.
But with that adoption came a hidden cost.
Kafka has become a massive reservoir of rich, high-fidelity operational data. The kind that could drive deep business insight.
Yet, today’s data architectures treat Kafka like a black box. Messages flow… but meaning gets stuck.
It’s ironic: the very platform that powers real-time experiences… keeps analysts waiting hours (or days) to see the same data. If they see it at all.
We offload it, clean it, reshape it, store it, sync it… All before anyone can ask a single question.
That’s the disconnect. And that’s what I believe we need to fix.
Two Worlds, One Problem
Ask any analyst what Kafka is or whether their company has real-time infrastructure, and many won’t know.
That’s not a knock. It’s a symptom.
The analytical world is disconnected from where data is created.
- Analysts live in dashboards, warehouses and batch jobs.
- They query structured tables. They think in terms of snapshots.
- Meanwhile, Kafka sits upstream, capturing real-time events, powering apps, and storing vast streams of operational truth.
And in between?
- Pipelines.
- Sync jobs.
- ETL chains.
- Staging tables.
- Duct tape.
The Result?
- Latency: by the time data lands in a dashboard, it’s already stale
- Blind spots: Many real-time events never make it downstream at all
- Drift: Ops and analytics teams operate on different versions of reality
The Architecture Is the Problem
It’s not that analysts don’t want real-time data.
It’s that today’s architecture makes it nearly impossible to get it.
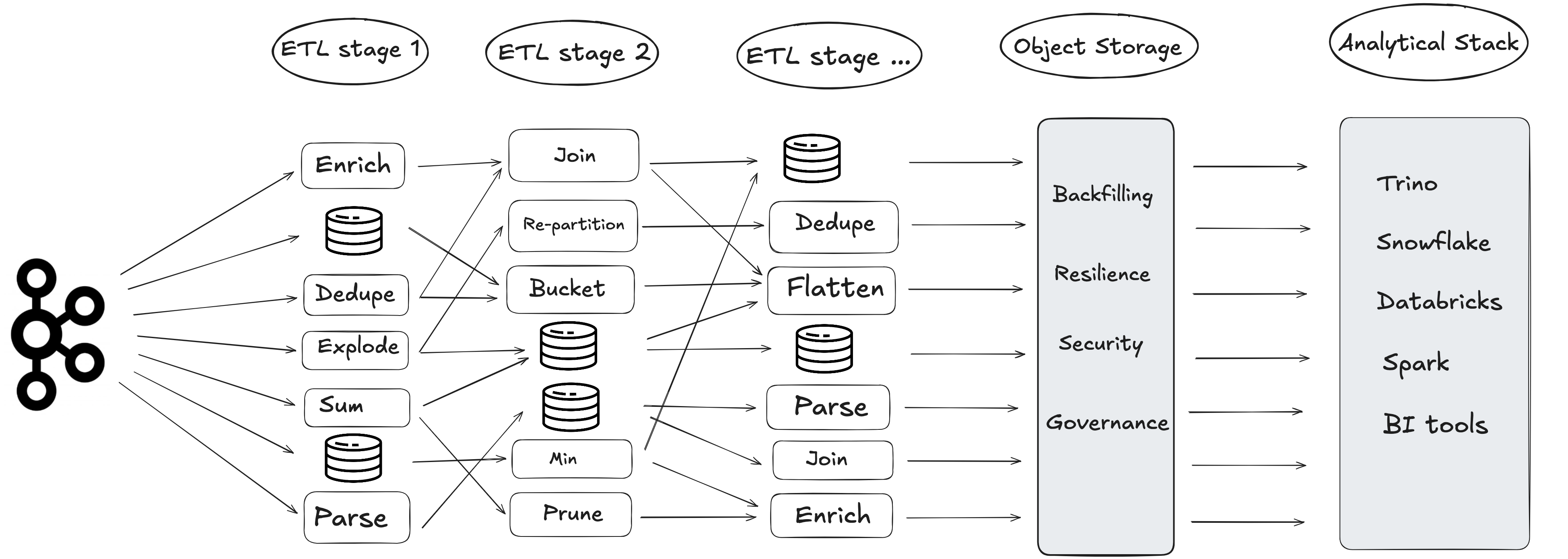
Here’s what happens in most companies:
- Data lands in Kafka — fast, raw and unstructured
- It’s dumped into cloud storage
- Then comes ETL, again and again:
- Parse
- Enrich
- Deduplicate
- Apply schema
- Repartition
- Eventually it’s loaded into a DWH
 The platform that powers real-time apps… keeps analysts waiting hours.
The platform that powers real-time apps… keeps analysts waiting hours.
By the time it’s queryable, you’ve lost speed, fidelity and often the original intent.
A simple question like “how many failed logins in the last hour?” becomes a batch job.
Or worse, not possible at all. The relevant Kafka topic wasn’t even replicated.
All the while, Kafka had the answer.
What If Kafka Was Queryable?
Imagine a world where you didn’t have to move the data, or transform it first.
Where analysts could:
- Connect Tableau and PowerBI directly to a Kafka topic
- Run SQL queries on raw events
- Explore live and historical data without waiting on sync jobs
It flips the model:
- From: move data to the tool
- To: bring the tools to the data
That’s the world I believe we’re heading toward.
Closer to the source. More flexible. Radically simpler.
👀 Want to see what querying Kafka directly can look like?
🔍 Check out the demo
📖 Learn more